September 20, 2017 weblog
Using Convolutional Neural Network to make 2-D face photo into 3-D wonder

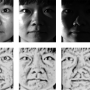
(Tech Xplore)—Oh my. Those who have sworn off 10-minute mental breaks that turn out to be 60-minute reveries had best avoid a fascinating new way to see how your face looks like in 3-D mode. A University of Nottingham and Kingston University team have actually come up with a way to turn a 2-D photo of a face into a 3-D model.
A new algorithm "learned" how to make a 3-D model from a flat image.
You can check out an online demo of their paper, thanks to the team. They said, "Please use a (close to) frontal image, or the face detector won't see you (dlib)."
The researchers have a paper out on their work and the paper is on arXiv. The title is "Large Pose 3-D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression," by Aaron S. Jackson, Adrian Bulat, Vasileios Argyriou and Georgios Tzimiropoulos.
3Ders.org said that "this new artificial intelligence (AI) algorithm is actually pretty exciting."
And where they merit some bragging rights is for "being able to turn a single two-dimensional image into a 3-D model. This, said 3Ders.org, has remained difficult for developers and challenged researchers in many fields.
The research team would agree. They stated in their abstract, "3-D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty."
How so? Current reconstruction systems, said the authors, must address "a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination."
The Verge's James Vincent wrote that "You usually need multiple pictures of the same face from different angles in order to map every contour. But, by feeding a bunch of photographs and corresponding 3-D models into a neural network, the researchers were able to teach an AI system how to quickly extrapolate the shape of a face from a single photo."
So how did they succeed? 3Ders.org said they trained a Convolutional Neural Network with datasets of 2-D facial images—and 3-D scans of the same faces. Key advantages of their CNN include its ability to work it out with just a single 2-D image of a face. It does not need accurate alignment.
Co.Design: "Because not all elements of the face are visible in a front-facing portrait, one of the algorithm's breakthroughs is that it can actual fabricate those hidden elements without the source material."
"The 3-D computer vision project really has to be seen to be believed," remarked Tristan Greene in The Next Web.
Aside from project page visitors having lots of fun with this, how might their development be applied in the real world, at least in theory?
The easy scenario to guess would be for use in creating virtual reality avatars for video games. But as 3ders.org noted, it could also be used in the cosmetic industry to virtually test makeup.
More information: Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression, arXiv:1703.07834 [cs.CV] arxiv.org/abs/1703.07834
Abstract
3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the availability of multiple facial images (sometimes from the same subject) as input, and must address a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination. In general these methods require complex and inefficient pipelines for model building and fitting. In this work, we propose to address many of these limitations by training a Convolutional Neural Network (CNN) on an appropriate dataset consisting of 2D images and 3D facial models or scans. Our CNN works with just a single 2D facial image, does not require accurate alignment nor establishes dense correspondence between images, works for arbitrary facial poses and expressions, and can be used to reconstruct the whole 3D facial geometry (including the non-visible parts of the face) bypassing the construction (during training) and fitting (during testing) of a 3D Morphable Model. We achieve this via a simple CNN architecture that performs direct regression of a volumetric representation of the 3D facial geometry from a single 2D image. We also demonstrate how the related task of facial landmark localization can be incorporated into the proposed framework and help improve reconstruction quality, especially for the cases of large poses and facial expressions. Testing code will be made available online, along with pre-trained models.
© 2017 Tech Xplore