May 17, 2017 weblog
Project Telepathy: Team explores bioelectric signals produced by facial muscles during speech

(Tech Xplore)—Researchers at the University of Bristol have figured out how you can whisper to someone up to 30 feet away. Their approach managed to translate facial expression into ultrasonic words.
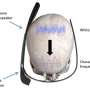
David Lumb in Engadget said the researchers built a wearable system; its components are a speaker worn on the forehead or chest and electrodes placed on the lips and jaw.
The only "snag," as New Scientist called it, is fairly substantial. How could one be a stellar secret message-passing agent in a crowd when staring people would find it odd that person is wearing a speaker on his head and walking around with electrodes around his mouth.
Nonetheless, a number of technology sites find their work most interesting. They have authored a paper, "Project Telepathy: Targeted Verbal Communication using 3-D Beamforming Speakers and Facial Electromyography." Authors are Anne-Claire Bourland, Peter Gorman, Jess McIntosh and Asier Marzo.
What makes their Project Telepathy work?
The authors described their research:
They tried out technologies for "targeted communication." How reliable was their approach? The authors said that "An electromyographic system composed of 4 surface electrodes had an accuracy of 80\% when discriminating between 10 words."
[New Scientist explained that "When tested, the system could recognise the correct word more than 80 per cent of the time, even if the person wearing the electrodes was only mouthing them."]
They also mentioned "the sound-through-ultrasound phenomenon to generate audible sound within a narrow beam."
They built a phased array of ultrasonic emitters. These could emit sound steered electronically without physically moving the array.
New Scientist: a person first attaches a speaker to the forehead or chest and four electrodes to lips and jaw.
Electrodes capture the electrical signals produced by the facial muscles as a person talks.
"Muscle tissue generates a difference in electrical potential between two points when the muscles contract or expand," the authors wrote. "This means that each word will have a unique electric pattern as a combination of the different muscle action potentials used to generate it."
New Scientist noted how the speakers emit ultrasound in a narrow beam, at a six-degree angle. That way, it is only people directly in its path who will hear the words.
This effort is still in prototype phase, however. Gwyn D'Mello in IndiaTimes: "The setup is still experimental and is currently only capable of recognizing around 10 basic words, and that too only 80 percent of the time."
Marzo and his colleagues, said New Scientist, used a machine learning algorithm trained to recognize which electrical muscle signals were associated with 10 words, including "back", "stop", "yes" and "no". Moving forward, "Later versions of the technology could detect a wider range of words and shrink the speaker system so that it could be built into clothing."
The authors stated that "accuracy in discriminating words still has to be improved if these systems had to be used in real scenarios."
They also hope that more progress in wearable transparent electrodes such as Second Skin will improve the signals and make the system less cumbersome. "The advances in smart textiles and wearable computing will also improve this aspect."
More information: Project Telepathy: Targeted Verbal Communication using 3D Beamforming Speakers and Facial Electromyography, CHI EA '17 Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, dl.acm.org/citation.cfm?doid=3027063.3053129
Abstract
Speech is our innate way of communication. However, it has limitation such as being a broadcast process, it has limited reach and it only works in air. Here, we explore the combination of two technologies for realizing natural targeted communication with potential applications in coordination of tasks or private conversations. For detecting words, we measure the bioelectric signals produced by facial muscles during speech. An electromyographic system composed of 4 surface electrodes had an accuracy of 80% when discriminating between 10 words. More importantly, the system was equally effective in discriminating spoken and silently mouthed words. For transferring the words, we used the sound-through-ultrasound phenomenon to generate audible sound within a narrow beam. We built a phased array of ultrasonic emitters, capable of emitting sound that can be steered electronically without physically moving the array. Two prototypes that combine detection and transfer of words are presented and their limitations analysed.
© 2017 Tech Xplore